


Evolution and Approaches of Data Architectures for Business Agility

In today's business world, organizational agility to adapt to market fluctuations is a fundamental pillar for achieving company objectives.
A crucial element of this flexibility is data architecture, which supports daily operations and facilitates strategic decisions through advanced data analysis. Over the past decades, we have witnessed considerable evolution in data architectures, responding not only to needs for efficiency and scalability but also to the pace of technical advancement.
Key Considerations in Choosing a Data Architecture
The choice of an appropriate data architecture must align with business objectives, ensuring the infrastructure's capacity to scale and adapt to future demands. Security and regulatory compliance are critical, ensuring that data is handled securely and in accordance with the law. Additionally, the infrastructure should facilitate the integration of new technological solutions without significant disruptions and be resilient to disasters to ensure business continuity under any circumstances.
These elements are vital for designing data architectures that not only meet current needs but also anticipate future market challenges and demands.
Evolution of Data Architectures: From Relational Warehouses to Data Mesh
Relational Data Warehouse
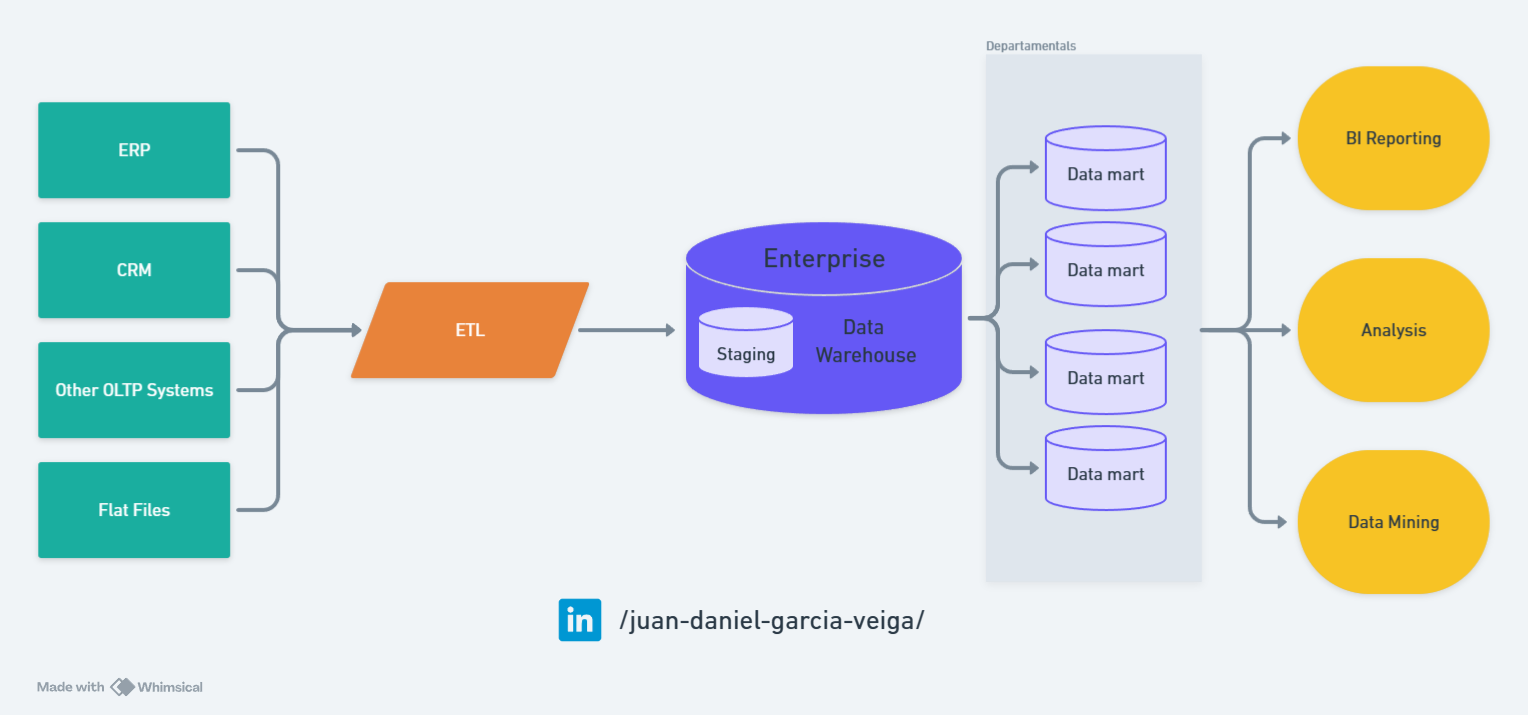
In the 1980s, relational data warehouses (RDWs) established themselves as a dominant solution in the technological field. Driven by the growing need to manage large volumes of information coherently and accessibly, these systems were characterized by a closely integrated storage and computing structure. They provided consistent and reliable transactions, essential for critical business applications. However, implementing these systems required extensive knowledge of SQL and database administration, along with high costs and scalability challenges as companies increased their data volumes.
Based on their main characteristics, relational data warehouses adopt a centralized approach that has proven crucial for applications demanding high data integrity and consistency. They operate under a predefined schema at the time of data entry into the system, ensuring that information is coherent and properly organized from the start. This contributes to low query latency thanks to the optimization of read operations.
Although this approach does not deliver immediate value, it stands out for its ease of development, supported by robust and well-documented environments provided by technologies such as Oracle Database, Microsoft SQL Server, and IBM DB2, which facilitate their implementation and management. However, the centralized nature and rigid write schema of relational data warehouses can limit their flexibility and scalability, especially in contexts where data volumes and processing needs are dynamic and constantly changing.
These systems are particularly valued in sectors such as finance, healthcare, and supply chains, where data accuracy and security are critical, and any error can result in severe consequences. Despite their challenges in terms of flexibility and scalability, relational data warehouses remain fundamental in the IT infrastructure of many organizations, providing a solid foundation for reliable analysis and informed decision-making.
Strengths:
High data consistency and reliability.
Extensive support and establishment in the industry.
Excellent for transactions and operations requiring data integrity.
Weaknesses:
Limited scalability and flexibility.
High maintenance and operation costs.
Difficulty handling large volumes of unstructured data.
Data Lake

Since the term was coined in 2011, data lakes have revolutionized data storage, offering essential flexibility. These systems allow the storage of large volumes of unstructured or semi-structured data without a predefined schema, using object-based storage. This method is not only economical and scalable but also separates computation from storage, requiring mastery of advanced tools like Hadoop and Spark to process and analyze the data. However, this innovation introduces significant challenges in areas such as security, governance, and data recovery, presenting major hurdles for companies.
Although data lakes enable flexible handling of different types of data, their approach can be considered centralized in the sense that all of an organization's data converges into a single massive repository. By utilizing object-based storage, these systems are specifically designed to manage schemas during the read process (schema on read), which facilitates storing data in its rawest form and structuring it only at the time of analysis. However, this can result in higher latency when accessing the data, as the processing and schema interpretation are performed during the query.
Despite the inherent latency, data lakes offer a quick time to value, crucial for exploratory analysis and handling large datasets where flexibility is prioritized over immediacy. The complexity of developing these architectures is considered intermediate, as organizing and managing data without a preset schema requires detailed planning and specific skills in handling data platforms.
Platforms like Amazon S3, Azure Data Lake, Google Cloud Storage, and Apache Hadoop are fundamental pillars in the data lake ecosystem. They not only provide the necessary storage space but also offer tools and capabilities to manage and process large volumes of data efficiently. Therefore, data lakes are particularly suitable for organizations seeking to gain predictive analytics and deeper insights, leveraging their ability to scale efficiently while handling different types of data.
Strengths:
Ability to store large volumes of data in its natural form.
Scalability and flexibility in handling structured and unstructured data.
Cost-effectiveness, especially on cloud-based platforms.
Weaknesses:
Risk of becoming "data swamps" if not managed properly.
Dependence on specialized technical skills for data extraction.
Modern Data Warehouse

The modern data warehouse, which emerged around 2011, combines the advantages of the structured storage of traditional data warehouses with the flexibility of data lakes. This hybrid approach enables scalable and versatile storage and computing, leveraging cloud technologies to increase efficiency and reduce costs. The combination of multiple technologies has also increased the demand for specialized skills in hybrid data management, analysis, and security.
Modern data warehouses offer a centralized solution that leverages the best of both worlds: data lakes and traditional data warehouses, integrating storage and processing capabilities into a single platform. This architecture employs both relational and object storage, adapting to schemas during both reading and writing. Although data latency can range from medium to high, these systems are designed to provide a low time to value, allowing companies to gain valuable insights from their data quickly and efficiently.
The development of these systems generally presents a medium level of difficulty, as they require careful integration of various technologies, but they are supported by interfaces and tools that facilitate their implementation and management. Key products such as Snowflake, Google BigQuery, and Amazon Redshift are leaders in the modern data warehouse market, offering robust solutions that enable companies to enjoy operational flexibility and improved query performance. These products are especially appreciated for their ability to handle large volumes of data and their efficiency in executing complex queries, making them ideal options for organizations looking to scale their data operations without compromising speed or accuracy.
Strengths:
Combine the advantages of data lakes and traditional data warehouses.
Robust support for BI and analytics with improved query performance.
Efficient integration of diverse data sources.
Weaknesses:
Complexity and cost in implementation and maintenance.
May require significant investments in data transformation and migration.
Data Fabric
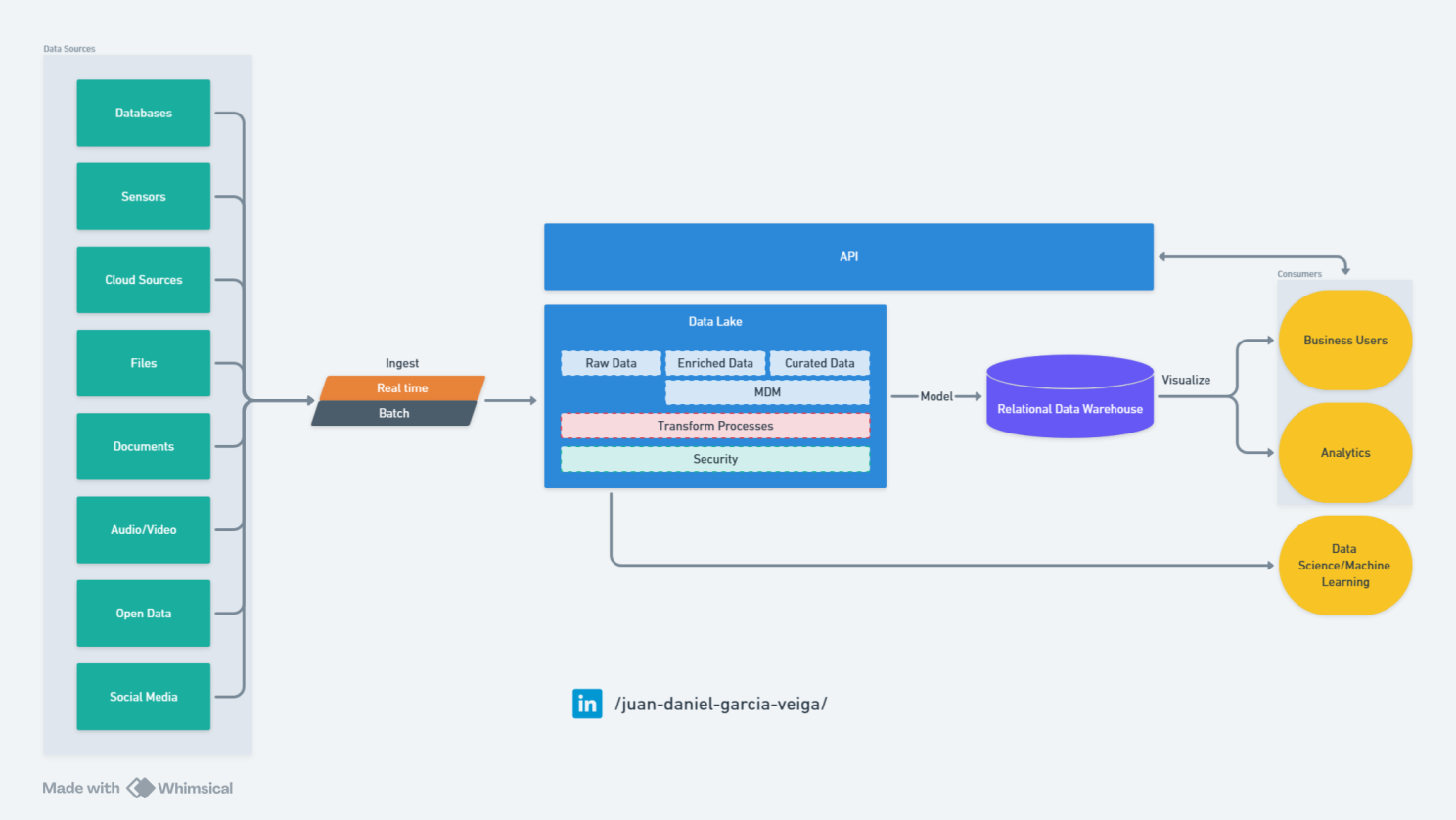
The data fabric approach, which emerged in 2016, has represented a significant advancement in data integration. These architectures offer a coherent framework for data access and management across various sources, integrating storage and computing into a unified view. This approach requires advanced competencies in data integration and security, as well as skills in distributed data platforms, increasing complexity but also analytical capability.
Data fabrics adopt a centralized strategy to manage and orchestrate data through a distributed infrastructure that links different data sources. This architecture uses both relational and object-based storage, implementing schemas during both reading and writing to optimize efficiency and flexibility. Data latency can range from low to medium, facilitating relatively quick access to information, which is essential for operations that demand real-time responses. Additionally, data fabrics are distinguished by their ability to quickly transform raw data into actionable insights, thanks to a low time to value.
However, developing data fabrics can be complex, with a level of difficulty ranging from medium to high due to the need to integrate and coordinate multiple systems and technologies. Key products such as Talend, Denodo, and Informatica play a crucial role in implementing these architectures, offering advanced tools for integration, management, and real-time data access. In conclusion, data fabrics are essential for companies seeking robust data management and effective integration of information from a variety of sources.
Strengths:
Advanced data integration across multiple sources and platforms.
Facilitates real-time access and more robust data management.
Supports efficient and secure data governance in complex environments.
Weaknesses:
High complexity in implementation and management.
Requires significant investment in technology and staff training.
Data Mesh
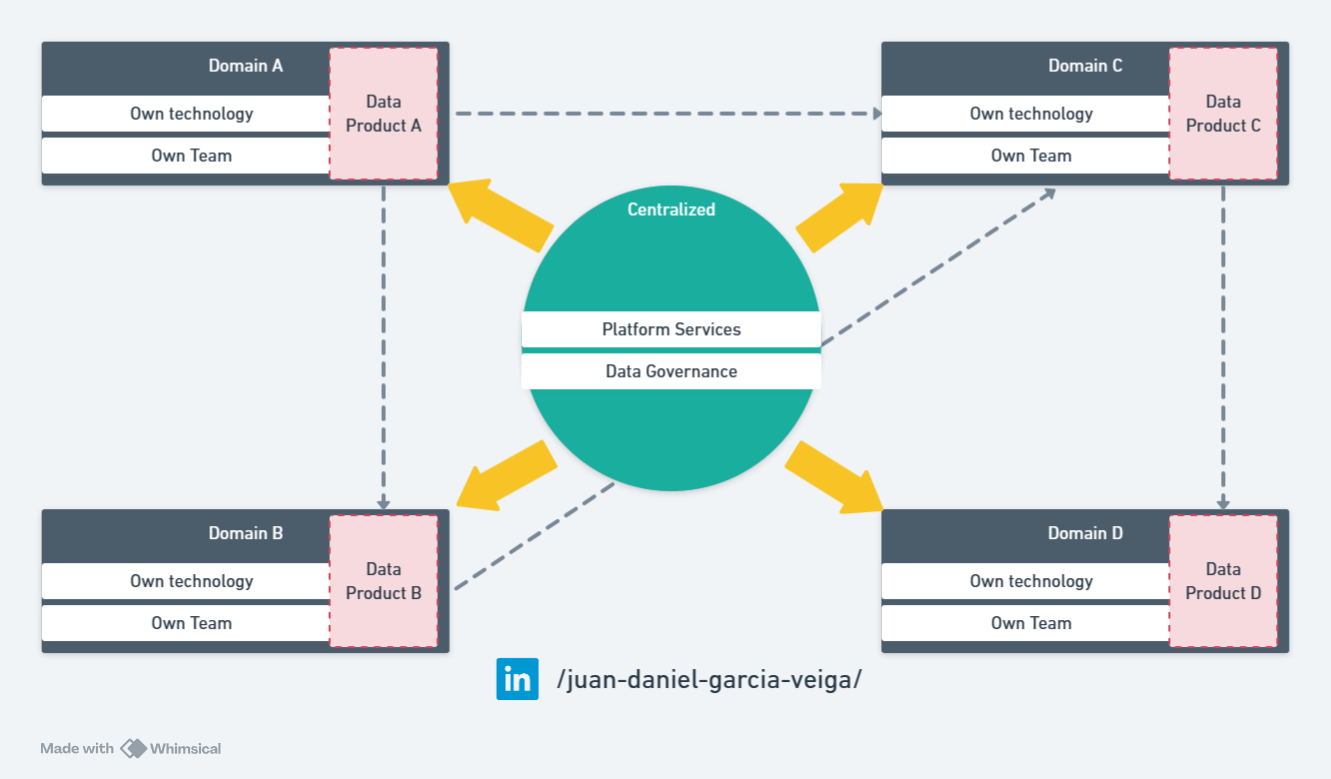
Introduced in 2019, the concept of data mesh emerged in response to the challenges of data management in large organizations facing scalability and agility issues. This innovative approach promotes team autonomy, allowing each functional domain within the organization to manage its own data lifecycle. By decentralizing data ownership, data mesh enables a faster response to the specific needs of each domain, significantly improving the agility and efficiency of large-scale data management. This approach emphasizes data as a product and data contracts.
In a data mesh, each business domain operates as its own center of data competence, with the responsibility to handle, model, and secure its data. This structure reduces dependency on a centralized data team, eliminating bottlenecks and distributing the data workload more equitably across the organization. Domains are incentivized to improve the quality and accessibility of the data they control, as it directly impacts their performance and outcomes.
The architecture of data mesh is characterized by its focus on interoperability and communication between independent domains. It uses a common data language and exchange protocol that facilitates integration and collaboration without sacrificing domain autonomy. Additionally, by applying principles of domain-driven design (DDD) to data architecture, each business unit can develop solutions that better fit its specific needs, improving efficiency in handling large volumes of data and accelerating the generation of valuable insights.
Despite its decentralized structure, a data mesh ensures consistency and compliance through universally applied security and governance policies. These policies are designed to be flexible and adaptive, allowing their implementation in each domain while maintaining rigorous security and privacy standards across the organization.
In addition to these features, the integration of DataOps into the data mesh architecture further reinforces collaboration and efficiency between domains. DataOps, by adopting DevOps principles in data management, optimizes the data lifecycle through process automation, continuous integration, and continuous delivery. This methodology fosters a culture of inter-domain collaboration, where the rapid provision of reliable, high-quality data is paramount. In the context of a data mesh, DataOps not only enhances each domain's ability to manage and secure its data effectively but also promotes seamless interoperability without compromising domain autonomy. By applying DataOps, data silos are overcome, and the generation of valuable insights is accelerated, ensuring that decision-making is agile and based on accurate, up-to-date data, keeping the organization at the forefront in a competitive market.
Within the Data Mesh approach, there are different topologies for structuring teams and distributing resources. These range from those that have the same organizational structure and use the same technology within each domain to those that offer total freedom within each domain.
Strengths:
Promotes a decentralized architecture that can scale effectively.
Facilitates autonomy and agility of different business domains in managing their data.
Improves the quality and speed of data access through localized management.
Weaknesses:
Requires significant organizational and cultural change.
High complexity in coordinating and governing data across multiple domains.
Lakehouse

The data lakehouse, developed in 2020, innovatively combines the efficient storage of a data lake with the computational power of data warehouses. This architecture aims to simplify data management and reduce costs while providing advanced querying and analytics capabilities. Implementing a lakehouse requires knowledge of emerging technologies such as Delta Lake, Apache Iceberg, and the management of large volumes of data in varied formats.
Data lakehouses represent a centralized data architecture that aims to overcome the limitations of both traditional data lakes and conventional data warehouses by combining elements of both to offer a more robust and flexible solution. They operate with object-based storage and under a read schema, facilitating efficient management of both structured and unstructured data. Although they present medium latency, data lakehouses stand out for their ability to deliver value quickly, thanks to their transactional improvements and more robust support for business intelligence (BI).
The difficulty of developing these systems is considered medium, as integrating the functionalities of a data warehouse with the flexibility of a data lake requires meticulous planning and execution. Products such as Databricks Delta Lake, Apache Hudi, and Apache Iceberg are fundamental in the implementation of data lakehouses, providing these transactional and schema management capabilities on platforms that traditionally did not offer them.
Strengths:
Combines the flexibility of data lakes with the structured management of data warehouses.
Supports a wide range of data types and analytical use cases.
Offers enhanced transactional capabilities and BI support over flexible storage.
Weaknesses:
Relatively new, with some technologies still developing and maturing.
May present challenges in integration with existing systems.
The evolution of data architectures in business environments continues to be driven by the need to handle increasingly larger and more complex volumes of data. Each new architecture raises the bar in terms of required skills and capabilities offered, challenging organizations to continuously evaluate their needs to choose the solution that best fits their strategic and operational objectives.